|
|
|
|
|
|
|
功能一览
|
|
|
|
|
|
数据前处理功能
|
|
功能
|
说明
|
|
清洗
|
对缺损值和异常值进行检查和修正
|
|
分组
|
对数据进行归类和范畴划分
|
|
采样
|
从数据中抽出一部分
|
|
正规化
|
对数据进行大小或分布上的变换
|
|
排序
|
对数据进行升序或降序的排列
|
|
数据文件分割
|
将数据分为学习用和验证用两部分
|
|
过滤
|
将符合所指定条件的数据提取出来
|
|
统合
|
将多个数据合成一个数据
|
|
数据列属性变更
|
变更数据列的性质、进行量化操作
|
|
数据处理加工
|
交互式的数据处理加工
|
|
再配置
|
对表中数据进行重新配置
|
|
匿名化
|
对数据进行加工,使其匿名化
|
|
日期及时间处理
|
对日期时间数据进行有关的计算处理
|
|
行选择
|
将满足条件的行抽取出来。可以对复数个表中的数据一次全部抽取出来
|
|
日期选择
|
将满足所指定条件的日期抽取出来
|
|
时间序列数据处理(基本操作)
|
可以表示时间序列数据的统计量和推移列
|
|
时间序列数据处理(线段表示)
|
用一组线段来近似时间序列数据
|
|
时间序列数据处理(距离计算)
|
将符合(或不符合)某个模式的时间序列数据抽取出来
|
|
|
|
|
数据挖掘处理功能-1
|
|
功能
|
说明
|
分组分析
(Classification)
|
Decision Tree
|
可做成多分枝的回归树、分类树。能够对应缺损值,和用户之间以对话形式进行分析
|
|
K-NN分析
|
根据近邻的k个值来建立回归模型和判别模型
|
|
神经网络
|
采用阶层型神经网络来建立回归模型和判别模型
|
|
Radial Basis Function Network
|
采用中间层的高斯函数来建立回归模型和判别模型
|
|
Support Vector Machine
|
采用支持向量来建立回归模型和判别模型
|
|
nuSVM
|
在支持向量机中的支持向量数可变
|
|
Support Ball Machine
|
采用聚类手法进行数据压缩,并与支持向量机方法一起来建立判别模型。该方法在处理大规模数据时尤为有效
|
|
预测
|
使用模型进行评价与预测
|
|
规则库预测
|
根据从学习用数据提炼出来的规则对未知数据进行分析、预测
|
|
模型集成
|
根据复数个模型间的权重比进行最优化的集团学习
|
|
Naive Bayes
|
考虑说明变量之间的相互依赖关系,根据朴素贝叶斯定理进行判别分析
|
|
交叉验证
|
利用不同的数据轮流重复进行学习,最后求得最合适的模型
|
|
Boosting
|
将复数个模型统合起来,求得一个高精度的模型
|
|
Bagging
|
使用复数个模型进行表决,根据少数服从多数的原则建立相应的避免过学习的模型
|
|
|
|
|
数据挖掘处理功能-2
|
|
功能
|
说明
|
|
统计量
|
统计
|
各个项目的计数、统计量计算(合计、平均、方差、最大、最小等)
|
|
相关
|
相关系数/卡方值/F值的计算
|
|
Feature Selection
|
搜索对目的变量有效的说明变量
|
|
簇间的比较
|
将数据分为复数的簇并自动将每个簇的特征提取出来
|
|
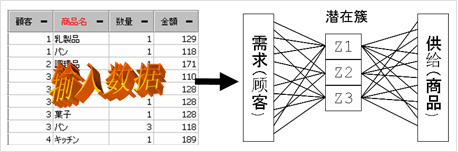
RFM分析
|
根据顾客购物的履历,从中筛选出优良顾客的信息
|
聚类分析
(Clustering)
|
BIRCH
|
先将数据进行压缩,然后对已经压缩过的数据采用K-Means法进行处理
|
|
K-Means法
|
指定k个簇,在此前提下对数据进行聚类处理
|
|
OPTICS
|
根据数据的密度进行聚类。特殊形状的簇也可以被抽取出来
|
|
自组织映射(SOM)
|
利用神经网络将数据映射在2维平面上
|
|
阶层化网络
|
根据各个街节点的连接情报,进行阶层型的聚类处理
|
|
One-Class SVM
|
使用支持向量,对未命中的值进行验证
|
|
阶层型聚类
|
进行阶层型聚类,结果用树状图标进行表示
|
|
Cluster Validation
|
对聚类进行评价
|
|
|
|
|
数据挖掘处理功能-3
|
|
功能
|
说明
|
|
组间关联分析(Association)
|
组间关联分析
|
抽取出多阶层间的关联规则(前提=>结论)
|
|
交互式规则分析
|
指定关联规则,在此前提下进行对话式探索
|
|
关联性图解分析
|
对指定的项目之间看其是否存在关联性
|
|
时间序列的组间关联分析
|
探索与时间序列有关的关联规则
|
|
簇间关联分析
|
对作为结论的列进行关联性分析
|
|
多变量分析
|
主成分分析
|
将数据中多个变量的信息归纳为少数的几个变量来表示
|
|
因子分析
|
从多变量数据众找到潜在的因子
|
|
对应分析
|
对定性数据量化后,进行主成分分析
|
|
Kernel主成分分析
|
使用核心法进行主成分分析
|
|
|
|
|
数据表示功能
|
|
功能
|
说明
|
|
数据视图
|
表及各种图形的表示
|
|
网络图形
|
网络形式数据的表示
|
|
S-PLUS图形
|
可以调用S-PLUS的图形功能
|
|
|
|
|
脚本语言功能
|
|
功能
|
说明
|
|
脚本语言
|
可定义自己的数据处理流程并重复执行
|
|
S的脚本语言
|
可直接调用执行S语言的脚本语言
|
|
外部脚本语言
|
可以调用R、SAS、NATLAB、Perl等脚本语言
|
|
|
|
|
插件
|
|
功能
|
说明
|
|
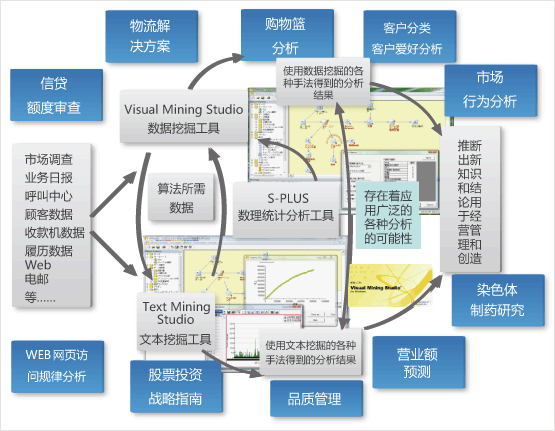
Text Mining Studio
|
可进行各种文本数据的分析
|
|
文本处理模块
|
可将文本数据转换为表的形式
|
|
BNModule
|
生成贝叶斯网络推理模型,进行概率推论
|
|
|
|
|
统计解析功能
|
|
·数据的基本运算及处理
|
·时间序列解析
|
|
·线形代数演算
|
·信号处理
|
|
·基本统计
|
·生存时间解析
|
|
·多变量解析
|
·检定
|
|
·回归分析
|
·品质管理图
|
|
·方差分析
|
·探索型的数据解析
|
|
|
·印象图形
|
|
|
·动态图形
|
|
|
|
|
其它功能
|
|
功能
|
说明
|
|
数据共享
|
可以对网络数据进行共享
|
|
批处理
|
根据指定的处理流程,可以对数据流进行外部批处理
|
|
数据库接续
|
通过ODBC可与数据库相连接。具有大容量、超高速的特征
|
|
批处理
|
可在外部直接运行所编制批处理文件
|
|
EXCEL接续
|
可直接对EXCEL文件的数据进行操作
|
|
文本整形
|
在某些情况下,可自动纠正文本数据中的输入错误
|
|
|
|
|
S语言与S-PLUS的小知识
|
|
·
|
S语言是由AT&T贝尔实验室开发的一种解释型语言,主要是用来进行统计分析、数据探索和作图。具有丰富的数据类型(数组、列表、向量、对象等),可以方便地实现用户自己的新的统计算法。交互式的运行方式、强大的图形功能使得用户能够方便的探索数据。 S-PLUS则是由美国公司开发的一种基于S语言的统计学软件,是世界上公认的三大统计软件之一。同S语言一样,其最大特点在于它可以交互地从各方面发现数据中的信息,并可以很容易地实现一个新的统计方法。S-PLUS主要用于数据挖掘、统计分析和统计作图等应用领域
|
|
·
|
本公司是S-PLUS在日本的总代理公司
|
|
|
|